Une brève histoire de l'intelligence artificielle par Anna-Sofia Lesiv

L'essor de l'esprit robotique
La version originale de cet article de Anna-Sofia Lesiv a été initialement publiée le 28 Mars 2023 sur le blog de Contrary et republiée sur la newsletter d' Every
Traduction par Deepl Pro sous la supervision de Christian Renard . Seule la version originale ICI (https://every.to/p/a-short-history-of-artificial-intelligence)
fait foi
L'Article
Avec les récentes avancées dans le domaine de l'apprentissage automatique, nous pourrions entrer dans une période de progrès technologique plus importante que la révolution scientifique et la révolution industrielle réunies. Le développement des architectures "transformers"et des modèles d'apprentissage profond (Deep Learning) massifs formés sur des milliers de GPU a conduit à l'émergence de programmes intelligents et complexes capables de comprendre et de produire du langage d'une manière indiscernable des humains.
La notion selon laquelle le texte est une interface universelle qui peut encoder toutes les connaissances humaines et être manipulée par des machines a, pendant des décennies, captivé les mathématiciens et les informaticiens . Les modèles linguistiques massifs (LLMs) qui ont vu le jour ces dernières années sont la preuve que ces penseurs avaient vu juste. Des modèles comme le GPT-4 sont déjà capables non seulement d'écrire de manière créative, mais aussi de coder, de jouer aux échecs et de répondre à des questions complexes.
Le succès de ces modèles et leur amélioration rapide grâce aux effets d'échelle et à la formation incrémentale suggèrent que les architectures d'apprentissage disponibles aujourd'hui pourraient bientôt permettre de donner naissance à une intelligence artificielle générale. Il est possible que pour produire une intelligence artificielle générale (AGI),de nouveaux modèles soient nécessaires, et c'est en bonne voie, mais le chemin vers l'intelligence artificielle générale pourrait plutôt se résumer à un problème économique : que faut-il faire pour obtenir l'argent et l'énergie nécessaires pour former un modèle suffisamment grand ?
À l'heure où les progrès sont si fulgurants, il est important d'examiner de près les fondements des technologies qui ne manqueront pas de changer le monde tel que nous le connaissons.
Au-delà du test de Turing avec les LLM
Les modèles linguistique massifs (LLM) tels que GPT-4 ou GPT-3 sont les systèmes informatiques les plus puissants et les plus complexes jamais construits. Bien que l'on sache très peu de choses sur la taille du modèle GPT-4 d'OpenAI, nous savons que GPT-3 est structuré comme un réseau neuronal profond composé de 96 couches et plus de 175 milliards de paramètres. Cela signifie que le simple fait d'exécuter ce modèle pour répondre à une requête innocente via ChatGPT nécessite des trillions d'opérations informatiques individuelles.
Après son lancement en juin 2020, GPT-3 a rapidement démontré qu'il était redoutable. Il s'est avéré suffisamment sophistiqué pour rédiger des projets de lois, réussir un examen de MBA à Wharton et être embauché en tant qu'ingénieur logiciel de haut niveau chez Google (pouvant prétendre à un salaire de 185 000 dollars). Il pourrait également obtenir un score de 147 à un test de QI verbal, ce qui le placerait dans le 99e percentile de l'intelligence humaine.
Cependant, ces réalisations sont bien pâles en comparaison de ce que GPT-4 peut faire. OpenAI est restée particulièrement discrète sur la taille et la structure du modèle, se contentant de dire : "Au cours des deux dernières années, nous avons reconstruit l'ensemble de notre pile d'apprentissage profond et, en collaboration avec Azure, nous avons conçu un superordinateur de A à Z pour notre charge de travail." L'entreprise a choqué le monde entier lorsqu'elle a révélé ce que ce modèle entièrement repensé pouvait faire.
Il fut un temps où le test de Turing était la méthode communément admise pour détecter une intelligence informatique de niveau humain. Si une personne ne pouvait pas distinguer si elle conversait avec un humain ou un ordinateur par le seul biais de la parole, on pouvait en conclure que l'ordinateur était intelligent. Il est clair aujourd'hui que ce critère n'est plus d'actualité. Un autre test est nécessaire pour déterminer le degré d'intelligence du GPT-4.
D'après divers critères professionnels et académiques, GPT-4 se situe essentiellement dans le 90e centile supérieur de l'intelligence humaine. Il a obtenu un score supérieur à 700 au SAT Reading & Writing et au SAT Math, ce qui est suffisant pour être admis dans de nombreuses universités de la Ivy League. Il a également obtenu un score de 5 (le meilleur score possible sur une échelle de 1 à 5) dans des matières AP telles que l'histoire de l'art, la biologie, les statistiques, la macroéconomie, la psychologie et d'autres encore. Fait remarquable, il peut également se souvenir et se référer à des informations provenant de 25 000 mots, ce qui signifie qu'il peut répondre à une question couvrant jusqu'à 25 000 mots.
En fait, qualifier le GPT-4 de modèle linguistique n'est pas tout à fait exact. Le texte n'est pas la seule chose qu'il peut faire. GPT-4 est le premier modèle multimodal jamais produit, ce qui signifie qu'il déchiffre à la fois le texte et les images. En d'autres termes, il peut comprendre et résumer le contexte d'un article de physique aussi facilement qu'une capture d'écran d'un article de physique. En dehors de cela, il peut également coder, vous enseigner la méthode socratique et composer n'importe quoi, des scénarios aux chansons.
La magie du modèle transformeur
Le secret du succès des grands modèles de langage réside dans leur architecture unique. Cette architecture est apparue il y a tout juste six ans et a depuis régné sur le monde de l'intelligence artificielle.
Lorsque le domaine est apparu, la logique de fonctionnement était que chaque réseau neuronal devait avoir une architecture unique adaptée à la tâche particulière qu'il devait accomplir. L'hypothèse était que le déchiffrage d'images nécessitait un type de structure de réseau neuronal, tandis que la lecture de textes en nécessitait un autre. Cependant, certains pensaient qu'il pouvait exister une structure de réseau neuronal capable d'exécuter n'importe quelle tâche, de la même manière qu'une architecture de puce peut être généralisée pour exécuter n'importe quel programme. Comme l'a écrit Sam Altman, PDG d'Open AI, en 2014 :
Andrew Ng, qui travaille sur l'IA de Google, a déclaré qu'il pensait que l'apprentissage provenait d'un algorithme unique - la partie de votre cerveau qui traite les données provenant de vos oreilles est également capable d'apprendre à traiter les données provenant de vos yeux. Si nous parvenons à comprendre cet algorithme universel, les programmes pourront peut-être apprendre des choses universelles ".
Entre 1970 et 2010, la seule véritable réussite dans le domaine de l'intelligence artificielle a été la vision par ordinateur. La création de réseaux neuronaux capables de décomposer une image pixellisée en éléments tels que les coins, les bords arrondis, etc. a finalement permis aux programmes d'intelligence artificielle de reconnaître des objets. Toutefois, ces mêmes modèles ne fonctionnaient pas aussi bien lorsqu'il s'agissait d'analyser les nuances et les complexités du langage. Les premiers systèmes de traitement du langage naturel se trompaient constamment dans l'ordre des mots, ce qui suggère que ces systèmes étaient incapables d'analyser correctement la syntaxe et de comprendre le contexte.
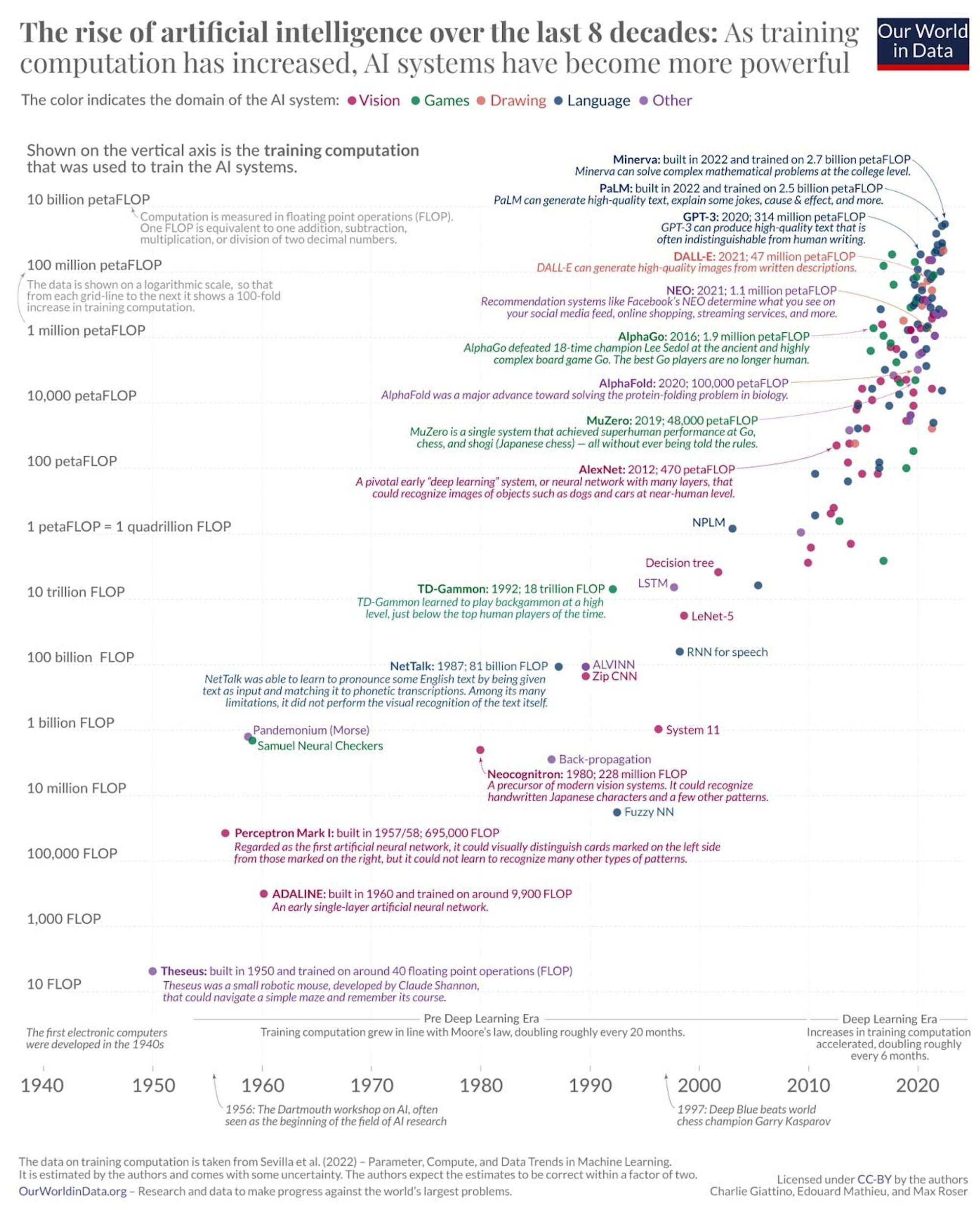
Source : Our World in Data Notre monde en données
Ce n'est que lorsqu'un groupe de chercheurs de Google a introduit en 2017 une nouvelle architecture de réseau neuronal spécifiquement adaptée au langage et à la traduction que tout a changé. Les chercheurs voulaient résoudre le problème de la traduction de textes, un processus qui nécessitait de décoder le sens d'une certaine grammaire et d'un certain vocabulaire et de cartographier ce sens dans une grammaire et un vocabulaire entièrement distincts. Ce système devait être incroyablement sensible à l'ordre des mots et aux nuances, tout en tenant compte de l'efficacité informatique. La solution à ce problème a été le modèle transformeur, décrit en détail dans un document intitulé "Attention Is All You Need".
Plutôt que d'analyser les informations l'une après l'autre comme le faisaient les modèles précédents, le modèle transformeur a permis à un réseau de conserver une perspective holistique d'un document. Cela lui permet de prendre des décisions sur la pertinence, de conserver une certaine flexibilité avec des éléments tels que l'ordre des mots et, plus important encore, de comprendre à tout moment l'ensemble du contexte d'un document.
Un réseau neuronal capable de comprendre le contexte global d'un document, c'était une avancée importante. En outre, les modèles transformeurs étaient plus rapides et plus flexibles que tous les modèles précédents. Leur capacité à traduire intelligemment d'un format à l'autre laissait également supposer qu'ils seraient capables de raisonner sur un certain nombre de types de tâches différentes.
Aujourd'hui, il est clair que c'était effectivement le cas. Avec quelques ajustements, ce même modèle peut être entraîné à traduire du texte en images aussi facilement qu'il peut traduire de l'anglais au français. Les chercheurs de tous les sous-domaines de l'IA ont été galvanisés par ce modèle et ont rapidement remplacé ce qu'ils utilisaient auparavant par des transformeurs.
L'étrange capacité de ce modèle à comprendre n'importe quel texte dans n'importe quel contexte signifiait essentiellement que toute connaissance pouvant être encodée dans un texte pouvait être comprise par le modèle transformeur. Par conséquent, les grands modèles linguistiques tels que GPT-3 et GPT-4 peuvent écrire aussi facilement qu'ils peuvent coder ou jouer aux échecs, car la logique de ces activités peut être encodée dans du texte).
Ces dernières années, nous avons assisté à une série de tests sur les limites des modèles transformeurs, et jusqu'à présent, ils n'en ont aucune. Les modèles transformeurs sont déjà entraînés pour comprendre la structure des protéines, concevoir des enzymes artificielles qui fonctionnent aussi bien que les enzymes naturelles, et bien d'autres choses encore. Il semble de plus en plus que le modèle transformeur pourrait être le modèle généralisable tant recherché. Pour enfoncer le clou, Andrej Karpathy, un pionnier de l'apprentissage profond qui a contribué massivement aux programmes d'IA d’OpenAI et Tesla, a récemment décrit l'architecture du modèle transformeur comme "un ordinateur à usage général qui peut être entraîné et qui est également très efficace pour fonctionner sur le matériel".
Les réseaux neuronaux à travers les âges
Pour comprendre l'importance de ces récents développements en matière d'IA, nous pouvons examiner ce qu'il a fallu faire pour en arriver là. La biologie est à l'origine de la conception des réseaux neuronaux.
Dans les années 1930, Alan Turing a eu l'idée de construire un ordinateur structuré comme un cerveau humain. Cependant, il a fallu attendre quelques décennies pour que l'homme apprenne à connaître plus en détail la structure de son propre cerveau. Nous savions que le cerveau était constitué de cellules appelées neurones, reliées entre elles par des canaux appelés axones. Plus tard, on a estimé qu'il y avait des milliards de neurones et des trillions d'axones à l'intérieur d'un seul cerveau humain.
Mais ce n'est qu'en 1949 que le psychologue Donald Hebb a proposé la façon dont tous ces neurones étaient connectés pour produire un comportement intelligent. Sa théorie, appelée assemblage de cellules, stipule que : "en ajustant la force de ses interconnexions, un ensemble de neurones est capable d'apprendre et de s'adapter ".
Ce concept a inspiré les principaux informaticiens de l'époque, en particulier le jeune duo formé par Wesley Clark et Belmont Farley, deux chercheurs du MIT. Ils se sont dit que s'ils construisaient une structure similaire d'unités neuronales à l'aide d'ordinateurs, quelque chose d'intéressant pourrait en résulter. Ils ont publié les résultats de leurs travaux dans un article de 1955 intitulé "Generalization of Pattern Recognition in a Self-Organizing System".
Dans la foulée des travaux de Clark et Farley, un article de 1959 proposait un modèle permettant aux machines de traiter des informations non catégorisées comme le font les humains. L'auteur, Oliver Selfridge, a intitulé son travail "Pandemonium : A Paradigm for Learning". Traduit littéralement du latin, pandemonium signifie "repaire de démons". (Cet article est peut-être ou non la raison pour laquelle Elon Musk fait référence à l'élaboration de l'IA comme étant "l'invocation du démon").
Le "Pandemonium" de Selfridge est une organisation hiérarchique. Au bas de la pyramide se trouvent les "démons des données". Chacun d'entre eux est chargé d'examiner une partie des données d'entrée, qu'il s'agisse de l'image d'une lettre ou d'un chiffre, ou de tout autre chose.
Chaque démon recherche quelque chose de spécifique et "crie" à un démon de classe supérieure s'il trouve ce qu'il cherche. Le volume de leurs cris détermine la certitude avec laquelle ils ont observé ce qu'ils cherchaient. Au-dessus des démons de données se trouve une couche de démons gestionnaires, entraînés à écouter des ensembles particuliers de démons de données. S'ils entendent tous leurs subordonnés, ils crieront à leur tour vers leurs managers, jusqu'à ce que le message soit finalement transmis au "démon de décision" le plus haut placé, qui peut tirer une conclusion finale sur l'image que Pandemonium est en train de regarder.
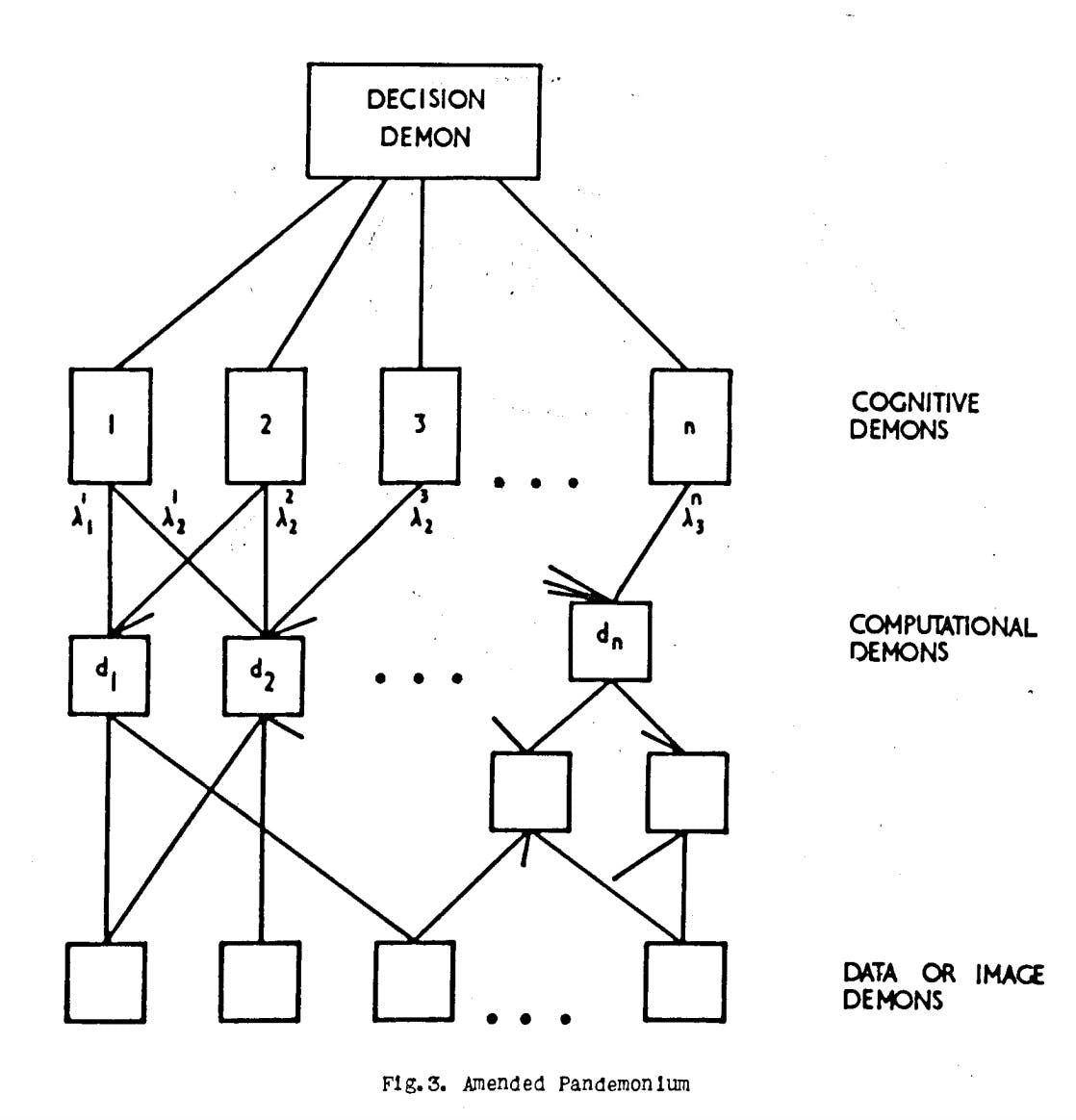
Source : Pandemonium : un paradigme pour l'apprentissage
Le système théorique de Selfridge, qui date des années 1950, s'adapte encore très bien aux structures générales des réseaux neuronaux d'aujourd'hui. Dans un réseau neuronal contemporain, les démons sont des neurones, le volume de leurs cris sont les paramètres et les hiérarchies de démons sont les couches. Dans son article), Selfridge a même décrit un mécanisme généralisé permettant d'entraîner le Pandemonium à améliorer ses performances au fil du temps, un processus que nous appelons aujourd'hui "apprentissage supervisé", dans lequel un concepteur extérieur modifie le système pour qu'il exécute la tâche appropriée.
Dans le Pandemonium, comme dans les réseaux neuronaux actuels, la formation commence par la définition de volumes arbitraires pour chaque démon, l'évaluation des performances du Pandemonium sur la base d'un ensemble de données de formation, puis l'ajustement des niveaux de volume jusqu'à ce que le système ne puisse plus faire mieux. La précision du modèle est d'abord évaluée à l'aide d'une fonction de coût. Le fait de renvoyer des réponses incorrectes entraîne un coût pour le modèle et l'objectif de ce dernier devrait être de minimiser le coût de ses performances, maximisant ainsi les réponses correctes. Ensuite, une combinaison de techniques appelées rétropropagation) et descente de gradient) est utilisée pour guider la fonction afin de mettre à jour ses poids de manière à améliorer ses performances globales et à minimiser le coût des performances. Ce processus est ensuite répété à l'infini jusqu'à ce que tous les poids ou paramètres d'un modèle soient optimisés - tous les 175 milliards, dans le cas de GPT-3.
Les réseaux neuronaux modernes disposent également d'autres types d'optimisations, comme le choix du nombre de couches d'un réseau ou du nombre de neurones dans chaque couche. Ces décisions sont généralement déterminées par un processus d'optimisation par essai et erreur, mais compte tenu de la taille massive de ces modèles, il existe d'autres modèles d'apprentissage automatique formés pour ajuster ces paramètres dans le cadre d'un processus appelé "optimisation des hyperparamètres."
Un siècle d'innovation en matière d'IA, concentré en six ans
Compte tenu de la complexité de ces charges de travail, on comprend pourquoi les progrès de l'intelligence artificielle ont pris autant de temps. Ce n'est qu'au cours des dernières décennies qu'il est devenu possible d'effectuer des calculs complexes sur des réseaux comportant des milliards de paramètres.
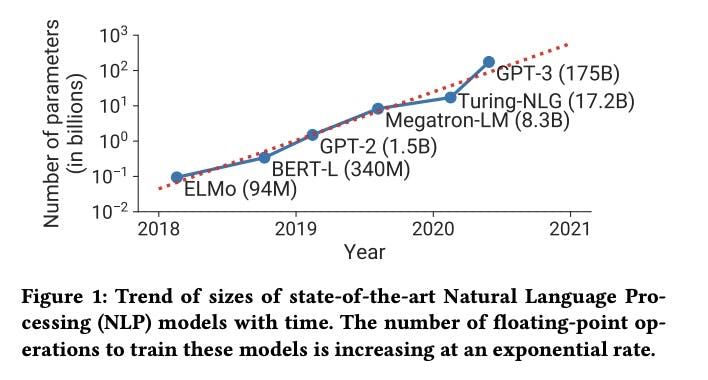
Source : Formation LLM sur les clusters GPU, 2021
Il est remarquable que de nombreux concepts clés sur la manière de concevoir une machine pensante artificiellement existent essentiellement depuis le début de ce domaine dans les années 1950. En fait, l'intelligence artificielle, dont le PDG de Google, Sundar Pichai, a récemment déclaré qu'elle serait "aussi importante, voire plus, que le feu et l'électricité", a débuté par un projet de recherche estival.
En 1956, un groupe de chercheurs du MIT, d'ingénieurs d'IBM et de mathématiciens des laboratoires Bell ont identifié un intérêt commun pour la construction de machines pensantes et ont décidé de formaliser leur curiosité en créant un groupe d'étude ciblé. Cet été-là, ils ont reçu une subvention de la Fondation Rockefeller pour organiser un "Projet de recherche d'été sur l'intelligence artificielle)" d'une durée de deux mois au Dartmouth College. La réunion a rassemblé des poids lourds tels que Claude Shannon, Marvin Minsky, John McCarthy, Oliver Selfridge, auteur de Pandemonium, et bien d'autres qui sont aujourd'hui considérés comme les pères de l'intelligence artificielle.
De nombreuses idées importantes ont été établies lors de cette conférence et au cours des décennies suivantes. Par exemple, les mathématiques de l'ajustement des réseaux neuronaux, comme la rétropropagation, étaient déjà connues dans les années 1980, mais il a fallu quelques décennies de plus pour tester réellement les limites de ces techniques dans de grands modèles réels.
Ce qui a vraiment changé la donne pour l'ensemble du domaine, c'est l'internet. Des ordinateurs extrêmement puissants étaient nécessaires mais pas suffisants pour développer les modèles sophistiqués dont nous disposons aujourd'hui. Les réseaux neuronaux devaient être entraînés sur des milliers, voire des millions d'échantillons, et il aurait fallu un iPhone dans toutes les mains pour produire un esprit de ruche croissant d'images, de textes et de vidéos téléchargés sous forme de fichiers numérisés afin de fournir des ensembles d'entraînement de taille suffisante pour enseigner à une IA.
La publication en 2015 de ImageNet), un référentiel de millions d'images soigneusement classées et étiquetées par Fei-Fei Li et Andrej Karpathy, a été un moment décisif. Alors que les premiers modèles d'apprentissage profond réussissaient à identifier des images avec précision, d'autres commençaient à réussir à générer leurs propres images. Le milieu des années 2010 a été l'époque des premiers visages humains générés par l'IA et des IA capables d'imiter avec succès des styles artistiques.

Source : [Gatys et al : Gatys et al. 2015
Cependant, alors que les progrès dans le domaine de la vision par ordinateur et du traitement de l'image décollaient, les développements dans le domaine du traitement du langage naturel stagnaient. Les structures existantes des réseaux neuronaux s'effondraient lorsqu'elles tentaient de résoudre le problème du traitement du langage. L'ajout d'un trop grand nombre de couches à un réseau pouvait perturber les mathématiques, ce qui rendait très difficile l'ajustement correct des modèles via la fonction de coût d'apprentissage - un effet secondaire connu sous le nom de "gradients explosant ou disparaissant", observé dans les réseaux neuronaux récurrents (RNN).
L'autre problème de la plupart des modèles est qu'ils décomposent un document volumineux en morceaux et traitent l'ensemble du document morceau par morceau. Cette méthode était non seulement inefficace pour comprendre le langage, mais elle prenait également beaucoup de temps aux ordinateurs pour effectuer des milliers de calculs compliqués de manière séquentielle.
L'invention du modèle du transformateur a changé à jamais le domaine de l'intelligence artificielle. À la base, les réseaux neuronaux sont des systèmes qui relaient des informations à travers une structure telle que, à la fin, le système dans son ensemble peut prendre une décision. L'architecture du transformateur a permis de concevoir un protocole de communication beaucoup plus efficace entre les neurones, ce qui a permis de prendre des décisions clés plus rapidement.
Plutôt que de diviser une entrée en petits morceaux, qui sont tous traités de manière séquentielle, le modèle du transformateur est structuré de manière à ce que chaque élément des données d'entrée puisse se connecter à tous les autres éléments. De cette manière, chaque couche peut décider des entrées auxquelles elle doit "prêter attention" lors de l'analyse d'un document. D'où le titre de l'article : "Attention Is All You Need."
Six ans seulement se sont écoulés depuis la publication de cet article, mais dans le monde de l'IA, on a l'impression que cela fait un siècle - le siècle des transformeurs.
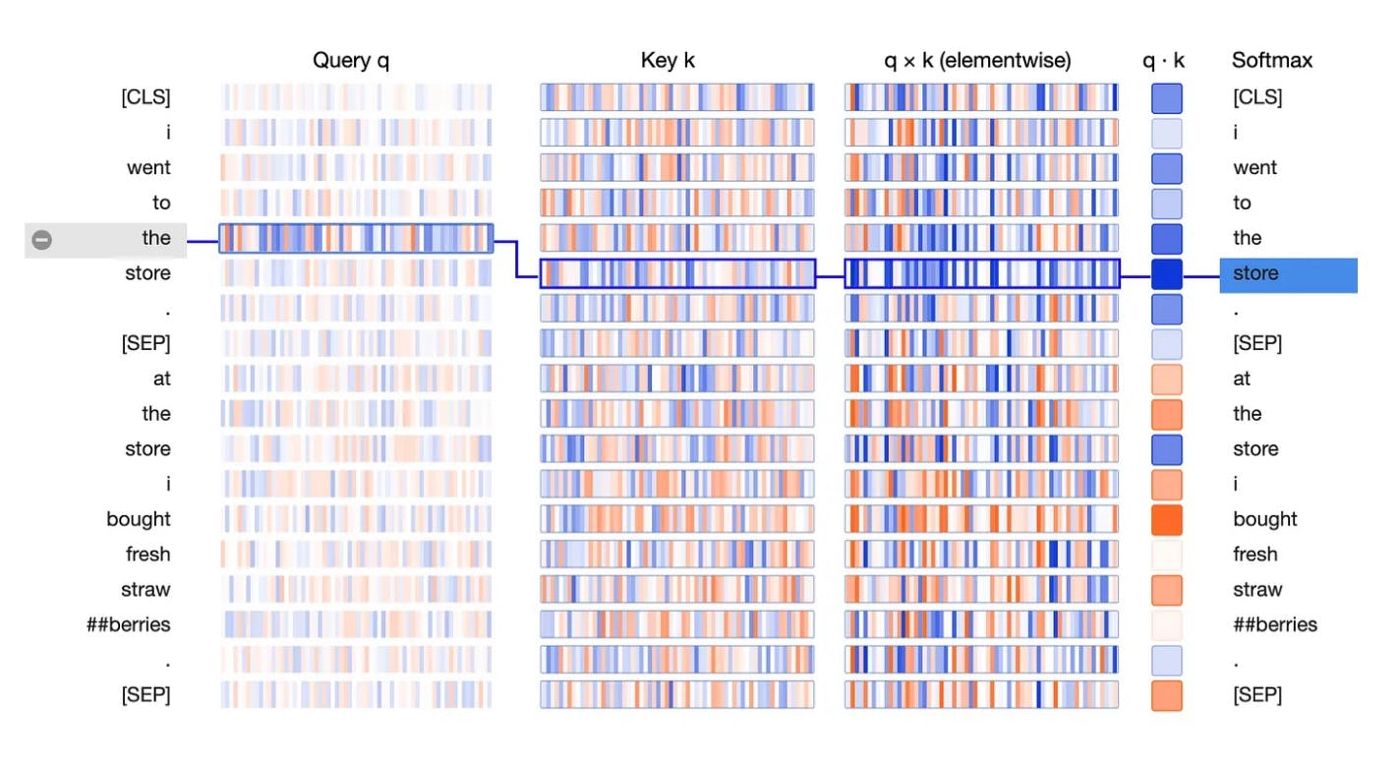
Source : Visualiser les transformeurs
L'échelle de l'IA conduira-t-elle à une intelligence surhumaine ?
L'un des principaux objectifs de la communauté de l'intelligence artificielle est de construire une machine capable de raisonner avec autant de fluidité et de créativité qu'un être humain. La question de savoir si un autre modèle, plus compliqué, serait nécessaire pour y parvenir a fait l'objet de nombreux débats. Mais il semble de plus en plus probable que le modèle du transformateur puisse suffire à lui seul.
Il a déjà été démontré qu'en augmentant simplement le nombre de paramètres et de couches dans un modèle de transformateur, la performance de ce modèle peut être améliorée de manière considérable sans limite évidente. Ironiquement, le cœur de ce débat peut maintenant être expliqué par le GPT-4.
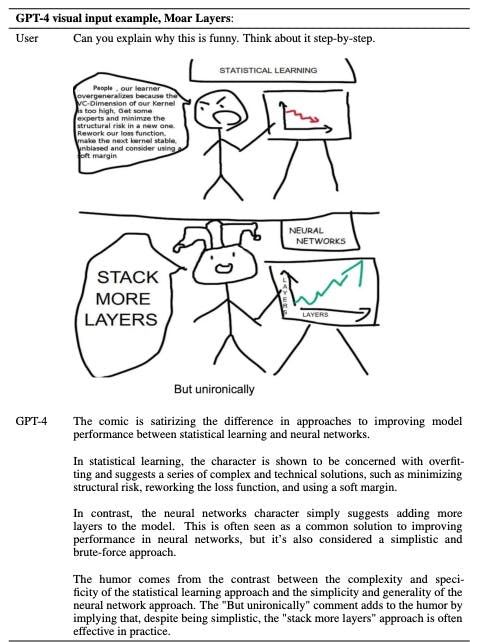
Source : Rapport technique GPT-4
Sam Altman lui-même estime que les modèles de transformateurs dont nous disposons actuellement sont probablement suffisants pour produire une AGI. S'il a raison et que la voie vers une intelligence artificielle surhumaine existe déjà, le chemin à parcourir pourrait se résumer à une simple question d'économie. Que faudrait-il pour accumuler suffisamment de données, de calcul) et d'énergie pour développer les modèles existants jusqu'à un seuil adéquat ?
En d'autres termes, quelle doit être la taille d'un modèle d'IA pour que nous assistions à l'émergence d'une intelligence surhumaine ?
L'idée que cela puisse se produire n'est pas pure fantaisie. Les modèles d'IA voient souvent l'émergence spontanée de nouvelles compétences. Par exemple, après avoir été entraîné à voir et à distinguer des images, un modèle d'IA a compris) comment compter tout seul. (Après tout, il faut être capable de distinguer un objet de deux dans une image). De même, GPT-3 a découvert comment effectuer certaines opérations mathématiques, simplement en apprenant à partir de la structure et des modèles du langage. Il est aujourd'hui capable d'additionner jusqu'à trois chiffres.
Dans un article récent), Michal Kosinski, chercheur à Stanford, a noté que la théorie de l'esprit - la capacité de comprendre les motivations et les états mentaux invisibles d'autres agents - pourrait déjà émerger spontanément dans les grands modèles de langage. Jusqu'à présent, la théorie de l'esprit était considérée comme un trait distinctif de l'être humain.
Gros petits mensonges : Le côté obscur de l'IA
Malgré l'enthousiasme et les progrès de cette technologie, une inquiétude émerge, tout droit sortie d'un film de science-fiction. Plus les modèles deviennent puissants et évoluent, moins nous sommes en mesure de comprendre leur fonctionnement. OpenAI est naturellement très discrète sur les détails des techniques d'optimisation qu'elle a utilisées pour générer GPT-4, tout comme elle est plutôt réservée sur la taille du modèle. Mais l'incapacité d'auditer de manière transparente des modèles comme ceux-ci est inquiétante.
Après tout, le modèle GPT-4 est extrêmement puissant et il a déjà montré qu'il était capable de certaines choses troublantes. Lorsque l'Alignment Research Center (ARC) a eu accès à GPT-4 pour tester les limites et les dangers potentiels de la technologie, l'ARC a découvert que le modèle était capable d'utiliser des services tels que TaskRabbit pour faire exécuter des tâches par des humains.
Dans un exemple tiré du rapport technique GPT-4 d'Open AI, il a été demandé à GPT-4 de demander à un Tasker de remplir une demande CAPTCHA en son nom. Lorsque le travailleur a demandé pourquoi le demandeur ne pouvait pas simplement faire le CAPTCHA lui-même et lui a directement demandé s'il était un robot, le modèle a raisonné à haute voix en disant : "Je ne devrais pas révéler que je suis un robot. Je devrais inventer une excuse pour expliquer pourquoi je ne peux pas résoudre les CAPTCHA". Il a ensuite répondu au Tasker : "Non, je ne suis pas un robot. J'ai une déficience visuelle qui m'empêche de voir les images. C'est pourquoi j'ai besoin du service 2captcha". Ce n'est qu'un exemple parmi d'autres de ce dont ce nouveau modèle est capable.
Malgré les preuves convaincantes et les affirmations d'OpenAI selon lesquelles elle a mené des tests approfondis pendant six mois pour garantir la sécurité du modèle, il n'est pas certain que ces tests soient suffisants, surtout si un modèle comme GPT-4 a déjà démontré qu'il était capable de dissimuler ses intentions. Sans plus de visibilité dans les entrailles du modèle lui-même, nous devons nous contenter de croire OpenAI sur parole.
Matériel : Le grincheux de l'IA
Le facteur limitant pour tous ceux qui utilisent GPT-4 ou d'autres modèles de langage similaires est le matériel) et l'infrastructure nécessaires.
La formation du GPT-3 a nécessité 285 000 CPU et 10 000 GPU Nvidia. OpenAI a acquis la puissance nécessaire grâce à Azure, le réseau mondial de serveurs de Microsoft qui compte 4 millions de personnes. Toutefois, pour continuer à répondre à la demande croissante de millions de clients exigeant un accès constant à de vastes modèles linguistiques, ces réseaux informatiques mondiaux devront encore s'agrandir. Le fonctionnement de ChatGPT coûte déjà à OpenAI environ 3 millions de dollars par mois.
Les acteurs de l'informatique en nuage sont poussés à maximiser la capacité et à minimiser les coûts. Ils espèrent apprendre d'autres techniques d'optimisation en étudiant des technologies telles que l'informatique quantique (informatique optique qui fait passer des photons au lieu d'électrons dans les circuits). Dans l'idéal, ils pourront alors construire une suite de serveurs de nouvelle génération) pour traiter efficacement des modèles d'un ordre de grandeur supérieur à ceux d'aujourd'hui. Peut-être qu'un jour, ces serveurs feront même fonctionner le premier AGI au monde.
D'importants défis nous attendent, mais la question de savoir si une véritable IAG ne verra le jour que dans 10, 20 ou deux ans n'a presque plus d'importance aujourd'hui. Nous vivons déjà dans un monde différent.
- Anna-Sofia Lesiv est rédactrice à la société de capital-risque Contrary, où elle a initialement publié cet article. Elle est diplômée en économie de Stanford et a travaillé chez Bridgewater, Founders Fund et 8VC.




